
By Darryl Brown
Our communication problem wasn’t too many meetings. It was Slack, our internal messaging platform.
More precisely, it was the fact that our process required Slack interactions to function. For many common stages in our process — a priority shift, a handoff, a release request — someone had to message someone else. The work couldn’t progress until a person intervened. And so people intervened, constantly, because that’s what the process asked of them. Nobody was doing anything wrong. The system just ran on human nudges, and Slack was where those nudges lived.
The specific friction points were familiar to anyone who has managed a software team. A project manager needed to communicate a priority change and that meant finding the right developer and messaging them. QA finishing a piece of work didn’t automatically signal anyone; someone had to notice and act. Releasing a feature required requesting it of the team member who held that responsibility, which cycled between team members. Every one of those moments was an interruption for both the sender and the recipient. Multiply that across a team of twenty people and dozens of active work items, and the noise adds up quickly.
The deeper issue was that each of those interruptions represented a gap in the process — a place where the system couldn’t carry information from one stage to the next on its own, so a person had to carry it instead.
We moved from Pivotal to ClickUp, but the tool change was almost beside the point. What mattered was how carefully we defined the process inside it. We built a Kanban board where all active work lived, prioritized and visible to everyone. But the more important work was defining the states a piece of work could be in at any given moment. We spent real time thinking through what each state meant, what triggered a transition, and critically: who needed to know when that transition happened.
Let me give a concrete example of what that thinking produced.
One of the most important states we introduced was “Merged.” When a developer merges code to the main codebase, the work is in a vulnerable position. It exists in between intention and reality. The code is committed but not yet in production. That moment deserved its own state, its own visibility, and its own automated response.
In the new process, the developer follows four steps:
- Merge changes to the main codebase.
- Test, if needed.
- Mark the work item to “Pending Deployment” in our board.
- Release the code by typing /release into Slack.
Within those steps, a lot of automation occurs in the background, giving the developer all the information they need to move through each step and release to production confidently. Notably, there is no communication with anyone else required. The developer does not need to reach out to a single person. The result was that everyone on the team received both the power and the responsibility to release code.
To appreciate why that matters, it helps to know what we replaced.
Previously, releases were a significant event. Over the course of a month, and sometimes up to three months, developers would merge work into a shared codebase. When the team decided enough work was ready, QA would test the entire batch together. Spreadsheets tracked names and versions by hand. A person was specifically assigned to each release, responsible for preparing and executing a lengthy set of release instructions. As often as not, something would go wrong mid-release, pulling in various people to troubleshoot. The release was a staged production itself.Now a developer types /release in Slack. That’s it.
Early on, there was hesitation about whether something that simple could really be trusted. I answered that question one afternoon when I took some time off to go mountain biking. In the middle of my ride, I pulled out my phone, typed into the Production Launch channel that I was doing the next release, tested the new command via Slack, and sent an irrelevant selfie from the trail. The release went fine. If the CTO can release code from atop a mountain bike, the process has genuinely changed.
The wider goal of reducing communication was simple in principle and harder in practice: a developer should be able to look at the board and know exactly what to work on next without anyone messaging them. QA should know when something is ready to test without being pinged. A priority shift should be visible to everyone the moment it happens, without a broadcast message.The process should carry the information, not people.
Another change I’m pleased with is one we built with n8n to address the code review problem.
Anyone who has worked on a software team knows the notification problem. The volume is extraordinary — review requests, comments, approvals, automated assignments. It becomes a firehose of information. I turned off all GitHub email notifications some time ago. They stopped being useful precisely because there were so many of them.
A little context for non-technical readers: when a developer completes a set of changes, those changes must be peer reviewed before they can be tested or released. A second set of eyes catches problems before they reach customers. Those review requests get assigned to another developer — and developers, reasonably given the noise, weren’t always responding quickly. Work sat waiting. There was no clear picture of where things stood.
Rather than creating a new reminder process or a policy about review turnaround times, we built an automation. At the start of each day, it looks at all open review requests, checks their status, and sends a single targeted Slack message to each developer summarizing everything pending — both requests waiting for their review and their own changes waiting on others. It also shows how long each has been waiting.
Here’s what that message looks like in practice:
Aldo Rojas — Outstanding code reviews
0 days old — reviews to complete:
- Fix form search field bug — IN REVIEW
- Add ability to restrict assets via cabinet menu — IN REVIEW
Reviews needing attention:
- Adding quarantined assets to quality checks — CHANGES REQUESTED
Your changes in review by others:
- Removing Missing Image / kept Missing Stencil Image — waiting 10 days
- Applying changes to traceability dashboard — waiting 11 days
We have a one business day expectation on review responses. The automation didn’t enforce that rule. It just made the current situation visible to the person who could act on it — specifically, clearly, and at the right moment.
That’s the principle I keep returning to, and it connects to something Rory Sutherland explores in his book “Alchemy,” which I’d recommend to anyone who thinks seriously about how behavior actually changes. Sutherland’s core argument is that humans are not rational optimizers. We respond to context, framing, and environment far more than we respond to incentives or explicit instructions. Small changes to what people see and when they see it often shift behavior more reliably than rules or consequences ever could. We didn’t tell developers to review faster. We just made it impossible not to notice when they hadn’t. The behavior changed because the visibility changed. Sutherland would not be surprised.
There’s a pattern in all of this worth naming.
Every place in our process where someone had to send a Slack message to make something move forward was a gap. Sometimes those gaps required human judgement to fill — context, relationship, nuance. More often, they just required the right information to arrive at the right place at the right time.
If your pipeline feels heavier than it should, it probably is. Start asking what actually needs to be there.
We didn’t try to reduce communication. We tried to make communication less necessary and less driven by people. When someone did reach out, it was because something genuinely required a person, not because the process had failed to carry information on its own.
Next: we took this further. Once we’d reduced the communication our process required, we turned to automating the repetitive tasks that were left. That’s what the next post is about.
By Darryl Brown
In my last post, I described my first step as CTO — holding a retreat to consider our current state and imagine a future one. This post is about what that retreat yielded, and what implementing those commitments unlocked.
When I stepped into the CTO role, one of the first things I wanted to understand was how we shipped software. Not just the mechanics, but the feel of it. How long did it take? What did it cost in effort and attention? What did it feel like to the people doing it? This wasn’t by chance. I had worked in that system, and felt it was ripe for improvement.
At the retreat, we started by discussing our current state honestly.
In the best scenario, we had a three-month cycle from the moment a piece of work became actionable to the moment it reached our customers in production. Work moved through multiple testing and validation stages, each supported by a complex infrastructure of custom-built tools and processes. Over the years we’d built hundreds of purpose-driven solutions to support that pipeline.
It wasn’t all bad. The defining principle of our process was quality. Our production error rate was near zero. That level of reliability wasn’t an accident. But there was a cost.
Because we shipped in large batches and staged work through long cycles, it was challenging and time-consuming to get a meaningful set of improvements out in a single release. We averaged one release per month.
The longer a piece of work lingered, the harder it became to ship cleanly. By the time changes entered their third month, they had to survive inevitable churn: other work moving, assumptions or requirements changing, dependencies shifting.
Then there was QA. By design, QA was our bottleneck. They couldn’t keep pace with the volume of work being completed. We had changes that were years old, not because they were bad ideas, but because we never had the bandwidth to test and release everything we’d built. In one memorable example, a developer left the company for three and a half years and returned shortly after I became CTO. He ended up shipping his own work four years after he’d originally written it.
This ponderous process carried its own risk. When you can’t ship quickly, you can’t respond quickly to bugs, to customer requests, to anything.
For my part, I was willing to accept some risk in exchange for speed. Ship faster, and perhaps we introduce more issues but we can respond faster too.
Prior to the retreat, I challenged the team to come up with proposals for how to make our process simpler. I’d used Vercel previously for small projects — a platform that makes deploying software effortless. Make a change, and it’s live. That simplicity creates a default expectation: shipping is easy, so you ship more often. I didn’t know if we could replicate that experience with a legacy product and real customers. But I was asking: could we get close? Could releasing software become something we did continuously, rather than something we prepared for over weeks?
At the retreat we talked openly about how painful the current process was, defining what those pain points were, then turning to imagining an improved future state. There were three days of discussion, iteration, and ideation. Presenting it here makes it sound straightforward. In practice, we had many false starts and tangents. Those were as important as the ideas we kept. All ideas were met with openness by the team. One key ingredient to these discussions was research done beforehand by key developers. They looked at how the best software teams in the world were solving these problems, and that guided much of our vision.
In the end, the team envisioned a future state built on two commitments:
- We would practice continuous development — shipping small, reliable improvements to customers on an ongoing basis rather than in large, infrequent batches.
- We would drastically simplify our delivery pipeline — challenging everything we’d built and keeping only what we could genuinely justify as adding value.
To implement continuous delivery, we adopted a workflow where every developer integrates small, frequent changes into a single shared version of the codebase, relying on automated checks to keep it always ready to ship. This has an important implication — there’s no room for a long testing cycle where work piles up and ships together. The size of each change must shrink. Testing must become continuous. Releasing must become easy and frequent.
To understand what this actually changed, it helps to know what we replaced. Previously, a developer would work on a set of changes for a minimum of three months. Those changes moved through multiple separate stages, each with their own infrastructure, before reaching customers.
Under the new approach, a developer completes a set of changes and submits them for review. Once approved, those changes are marked ready for testing. QA picks them up, merges them into the shared codebase, which triggers an automated build, and starts testing immediately. When tests succeed, the changes are released straight to customers. The typical cycle is a few days to a few weeks, not months.
The reaction from the team as we started implementing these changes was telling. The team was enthusiastic, but we also felt uncomfortable with the speed. It felt almost like we were doing something we shouldn’t be. Work was reaching customers so quickly that people kept waiting for someone to say it wasn’t allowed. I was the only one who could have said that, and I didn’t want to.
It is worth naming again that these ideas came from the engineers who had built the original pipeline. The same people who had designed and maintained that complex system were the ones who proposed replacing it. I think that happened because the retreat created two conditions that had been missing. First, genuine space to say “we could do this differently.” Second, a belief that the team had the support and the will to actually make the changes. Once those conditions were met, they didn’t need me to tell them how. They knew better than anyone where the pain lived.
We started the transition in late January. The technical lift was not trivial, but it was accomplished in weeks. And much of the effort was less about building something new and more about removing what we no longer needed. Simplifying. Deleting. Unwinding complexity that had accumulated over years.
That was a lesson I’ve carried since: unwinding complexity is much faster than building it.
Once the streamlined pipeline was in place, the workflow changed. When any pending work was tested, we would release it immediately. I’ll write separately about the process and communication changes that made this flow smoothly — that’s its own post.
The results were immediate and significant.
Within about a month, we went from one release per month to several releases per day.
These changes had a cumulative and dramatic impact on productivity. Over the first quarter of 2024, the number of completed work items reaching production nearly doubled. And, it kept going up. By the end of 2024, we had a sustained throughput gain of roughly 4 times compared to our previous baseline.
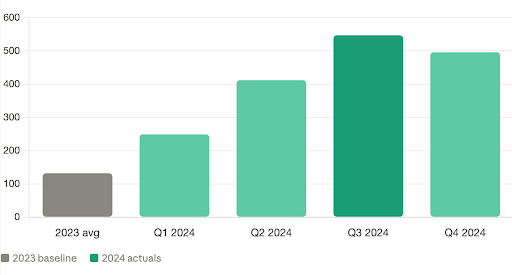
Here’s the part that surprised me most: our bug rate didn’t go up. It effectively went down. We had roughly the same number of bugs per month as before, but we were shipping four times the work. The same absolute number of issues across four times the output is a dramatically better ratio. That wasn’t luck, but we had not predicted it.
I can’t say for certain why this occurred. I postulate that when you ship in smaller pieces, faster, you reduce the surface area of potential failure. You find issues earlier, while context is fresh. And you avoid the hidden complexity that comes from batching changes together for weeks. Shipping faster didn’t make us sloppy. It made us sharper. LEAN manufacturing has known this for decades — small batch sizes and reduced work in progress are foundational principles for a reason. We just applied them to software.
Harder to measure — but just as real — was what happened to the team.
Developers were seeing their work reach customers quickly. The feedback loop tightened. The reward came faster. They spent less time navigating process and more time solving problems.
Any developer will tell you: they want to spend their time solving problems — not fighting the pipeline or the process, not watching their work sit untouched for months.
Momentum creates pride. Pride creates ownership. Ownership creates quality.
We didn’t do this because we wanted to go faster. We did it because we wanted a healthier system that we enjoyed working in. The consequence was a system where progress was visible, learning happened quickly, and we didn’t have to choose between reliability and delivery.
We still care deeply about quality. That didn’t change. What changed is how we achieve it.
In “The Phoenix Project,” Gene Kim describes how work piling up at a single constraint compounds across the entire system. QA was our bottleneck by design — a safety net the organization treated as a feature, not a flaw. That wasn’t wrong. It produced a near-zero production bug rate. But it came with a cost to our team enjoyment and throughput that we eventually decided to address differently. Relieving that constraint didn’t lower our standards. It let us meet them more consistently.
Sometimes the safest thing you can do isn’t to slow down. It’s to shorten the distance between start and finish – in our case – building, shipping, and learning.
If progress only shows up in big moments, it’s going to feel slow. Make it visible more often.
In my next post I will share how we redesigned our process to reduce the human communication our workflow required, and what happened when we did.
By Darryl Brown
I became CTO in January 2024. My first major act was to call a team retreat and spend most of it listening. It was the only honest option I had.
I’d been with the team for seven years, first as a developer, then as Director of Software. I knew the people, the product, the technical debt. What I didn’t know yet was what the view looked like from the CTO seat. And I’d learned enough in my first month to know: I didn’t have the information yet to lead with answers.
So I came in with a strong sense of trust in my team, and I listened with an open mind.
I didn’t conjure that approach from thin air. My CEO and the executive team gave me genuine latitude to figure out what needed doing and do it. The trust I was trying to extend to my team started with them.
The retreat happened at the end of my first thirty days. I asked the team to come with open minds and honest assessments of our process, our pipeline, our ways of working. I also conveyed that I was willing to allocate team resources to process and infrastructure improvement. This is not easy as we all know. We, like all teams everywhere, have an unending amount of work on our docket. The team needed to believe that I was willing to commit resources to making these improvements.
That commitment is harder than it sounds. Resources take away from customer deliverables, which drive revenue, which keeps us in business. Stephen Covey writes in “First Things First” about the difference between what is urgent and what is important — and the tendency of urgent work to crowd out important work indefinitely. Process improvement is almost never urgent. There is always a customer deliverable that feels more pressing. And so process improvement gets shunted, year after year, until the cost of not improving becomes impossible to ignore. We had done that. I felt the payoff potential was worth the investment, and it was the kind of team I wanted to be a part of — experimental, improving, dynamic.
The good stuff started to happen after I stopped talking. They had ideas. Not mild suggestions but real, considered, sometimes radical ideas about how things could be different. They’d been thinking about this for a while. What they hadn’t had was a chance to believe these ideas might come to fruition.
Organizations develop rhythms over time. Ways of working become familiar, and familiar things become hard to question, not because anyone decides they’re untouchable, but because that’s just how systems tend to calcify. The team wasn’t stuck because they lacked answers. They were waiting for the conditions to share them — to believe change was possible. I think about Simon Sinek’s concept of the Circle of Safety here — the idea that people will only take creative risks when they are in a trusting environment.
One way we incorporate this trust is in how we frame management decisions. We first present them as proposals to our team and ask for feedback. Occasionally someone raises a concern, and in our experience, those concerns are typically valid. When that happens, we try to iterate in the moment. If a clear path forward doesn’t emerge right there, we form a working group to explore options — a diverse group with the most useful perspective on the problem. The idea comes back revised.
We extended this same approach beyond the development team. Our development organization had fallen into a habit of making decisions and announcing them — decisions that affect other departments: operations, sales, customer success. There were probably good reasons that pattern existed before I arrived, but it wasn’t serving the company well anymore. So we tried to apply the same principle outward: treat cross-departmental changes as proposals too, invite the people affected to weigh in, and iterate when useful. It made for slower decisions occasionally. It made for much better ones, and facilitated buy-in from others since they had participated. LEAN practitioners call this respect for people — the principle that the people closest to a process have the most valuable insight into how it should change. We just extended that respect beyond our own team.
That process — propose, invite objection, iterate — isn’t a formal policy. It’s a habit of framing. It changed the dynamic from a “here is what we are doing” to “what do you think of this?” That shift in framing changed what our meetings felt like. People who had been recipients of decisions became participants in them, and the quality of what we built together reflects that.
I’ll write more about what the retreat’s commitments looked like in practice in my next post.
Spoiler alert: the ideas for specific transformations were not mine. They came from the engineers who had built and been living inside the system. My job was to create the right conditions for the team to generate the answers.
The results were extremely positive. The increase in productivity was something I and our board members appreciated. But at a more fundamental level, the changes affected the team itself. A senior developer put it best: “Once we realized we could change and be successful, it spawned a culture of experimentation that’s now embedded.” There is a palpable momentum that started after we implemented the changes from that retreat, and it is still here today.
I believe a critical part of being a leader is making it easy for the people around you to do what they’re capable of. Sometimes that means having the right answer. More often, it means getting out of the way.
If your team already has the answers, your job might be to make it safe enough for them to say them.
This is a series of what I’ve learned, and what my team taught me, over the last two years.
By Darryl Brown
In 1993, I graduated with a Master’s degree in Artificial Intelligence. At the time, that was a great way to confuse people at parties. AI was an academic curiosity, not an industry. Nobody was hiring for it. I pivoted into traditional software development. I spent the next two decades working through many startups, including running my own web design and development company. I eventually landed at TRU Solutions ten years ago as a developer. I became Director of Software, and two years ago I became CTO.
I’m writing this series for two reasons.
The first is to learn from what we have done. Reflecting on what our team has accomplished over the last two years — writing it down, putting it in order — is how I hope to not lose sight of how we did it. The practices that changed everything could quietly become the new normal, and the thinking behind them fades. I don’t want that to happen. So I’m writing it down.
The second is a small act of gratitude. This industry has given me an extraordinary career over thirty-five years. Hopefully, something in these posts will prove useful to someone in that journey — a developer who wants to lead, a new CTO figuring out the role, someone trying to understand why their team isn’t moving the way they want it to.
Ten posts. Ten lessons. Each one is about something specific: how we simplified our release pipeline, how we redesigned our process to reduce friction, how we approached automation, AI adoption, quality engineering, and more. As I’ve reflected on all of it, I’ve come to think there’s a single thread running through every one of those changes.
We started asking why.
I should mention that I had an unfair advantage in recognizing that thread. My partner (and fiancée) works as an operations improvement consultant and is a LEAN manufacturing expert. As I described changes we were making, she would help me understand how they connected to LEAN principles — small batch sizes, eliminating waste, continuous improvement, creating safety to experiment and fail. What I was doing intuitively, she could validate and name. I got regular free consulting from someone with deep expertise in the subject, and the combination of her knowledge and my instincts turned out to be a great combination. The LEAN principles didn’t drive our transformation from the top down — but looking back, they were present in almost every decision we made. I’ll point to those connections throughout the series.
The other significant influence on my thinking was Simon Sinek. I’ve read several of his books, but Leaders Eat Last struck the deepest chord. His human-centric approach to leadership — the idea that a leader’s primary job is to create an environment where people feel safe, valued, and able to do their best work — helped me find my own why as a CTO. And my why turns out to have little to do with technology. It is about my people and my company. It is about following the principles I have come to believe in deeply — protecting and lifting up the people I work with, excelling together as a team, and serving one another in this shared endeavor – capitalism as a force for good. The technology is the vehicle. The people are the point. You’ll see Sinek’s influence throughout this series, particularly in the posts about culture, safety, and leadership.
And it turns out that leading with people in mind and leading with curiosity are not separate things. The same orientation that asks ‘what does my team need?’ also asks ‘why are we doing it this way?’ Both questions start from the same place — a refusal to accept the status quo without understanding it.
Why are we walking code through five separate environments before it reaches production? Why does this ticket prescribe how something should be built before we’ve understood what problem we’re actually solving? Why can’t releasing software be as simple as merging to a branch? These questions, asked genuinely, repeatedly, at every level of the team, turn out to be a powerful tool. It surfaces assumptions. It exposes complexity that exists out of habit rather than necessity. It creates the conditions for people to propose better answers.
I don’t think I would have named “ask why” as our guiding philosophy while we were in the middle of it. I was applying it deliberately in specific moments without recognizing it as the theme. It took stepping back to write this series to see it clearly. Which is, I suppose, its own small argument for reflection
If any of this feels familiar, I’ll walk through exactly how we applied it in the posts that follow.
The posts that follow are about what we did and, more importantly, how we did it. The what is interesting. The how is what’s actually useful. I hope something here earns its place in your thinking.
