
Reduce Complexity: From One Release a Month to Many a Day
By Darryl Brown
In my last post, I described my first step as CTO — holding a retreat to consider our current state and imagine a future one. This post is about what that retreat yielded, and what implementing those commitments unlocked.
When I stepped into the CTO role, one of the first things I wanted to understand was how we shipped software. Not just the mechanics, but the feel of it. How long did it take? What did it cost in effort and attention? What did it feel like to the people doing it? This wasn’t by chance. I had worked in that system, and felt it was ripe for improvement.
At the retreat, we started by discussing our current state honestly.
In the best scenario, we had a three-month cycle from the moment a piece of work became actionable to the moment it reached our customers in production. Work moved through multiple testing and validation stages, each supported by a complex infrastructure of custom-built tools and processes. Over the years we’d built hundreds of purpose-driven solutions to support that pipeline.
It wasn’t all bad. The defining principle of our process was quality. Our production error rate was near zero. That level of reliability wasn’t an accident. But there was a cost.
Because we shipped in large batches and staged work through long cycles, it was challenging and time-consuming to get a meaningful set of improvements out in a single release. We averaged one release per month.
The longer a piece of work lingered, the harder it became to ship cleanly. By the time changes entered their third month, they had to survive inevitable churn: other work moving, assumptions or requirements changing, dependencies shifting.
Then there was QA. By design, QA was our bottleneck. They couldn’t keep pace with the volume of work being completed. We had changes that were years old, not because they were bad ideas, but because we never had the bandwidth to test and release everything we’d built. In one memorable example, a developer left the company for three and a half years and returned shortly after I became CTO. He ended up shipping his own work four years after he’d originally written it.
This ponderous process carried its own risk. When you can’t ship quickly, you can’t respond quickly to bugs, to customer requests, to anything.
For my part, I was willing to accept some risk in exchange for speed. Ship faster, and perhaps we introduce more issues but we can respond faster too.
Prior to the retreat, I challenged the team to come up with proposals for how to make our process simpler. I’d used Vercel previously for small projects — a platform that makes deploying software effortless. Make a change, and it’s live. That simplicity creates a default expectation: shipping is easy, so you ship more often. I didn’t know if we could replicate that experience with a legacy product and real customers. But I was asking: could we get close? Could releasing software become something we did continuously, rather than something we prepared for over weeks?
At the retreat we talked openly about how painful the current process was, defining what those pain points were, then turning to imagining an improved future state. There were three days of discussion, iteration, and ideation. Presenting it here makes it sound straightforward. In practice, we had many false starts and tangents. Those were as important as the ideas we kept. All ideas were met with openness by the team. One key ingredient to these discussions was research done beforehand by key developers. They looked at how the best software teams in the world were solving these problems, and that guided much of our vision.
In the end, the team envisioned a future state built on two commitments:
- We would practice continuous development — shipping small, reliable improvements to customers on an ongoing basis rather than in large, infrequent batches.
- We would drastically simplify our delivery pipeline — challenging everything we’d built and keeping only what we could genuinely justify as adding value.
To implement continuous delivery, we adopted a workflow where every developer integrates small, frequent changes into a single shared version of the codebase, relying on automated checks to keep it always ready to ship. This has an important implication — there’s no room for a long testing cycle where work piles up and ships together. The size of each change must shrink. Testing must become continuous. Releasing must become easy and frequent.
To understand what this actually changed, it helps to know what we replaced. Previously, a developer would work on a set of changes for a minimum of three months. Those changes moved through multiple separate stages, each with their own infrastructure, before reaching customers.
Under the new approach, a developer completes a set of changes and submits them for review. Once approved, those changes are marked ready for testing. QA picks them up, merges them into the shared codebase, which triggers an automated build, and starts testing immediately. When tests succeed, the changes are released straight to customers. The typical cycle is a few days to a few weeks, not months.
The reaction from the team as we started implementing these changes was telling. The team was enthusiastic, but we also felt uncomfortable with the speed. It felt almost like we were doing something we shouldn’t be. Work was reaching customers so quickly that people kept waiting for someone to say it wasn’t allowed. I was the only one who could have said that, and I didn’t want to.
It is worth naming again that these ideas came from the engineers who had built the original pipeline. The same people who had designed and maintained that complex system were the ones who proposed replacing it. I think that happened because the retreat created two conditions that had been missing. First, genuine space to say “we could do this differently.” Second, a belief that the team had the support and the will to actually make the changes. Once those conditions were met, they didn’t need me to tell them how. They knew better than anyone where the pain lived.
We started the transition in late January. The technical lift was not trivial, but it was accomplished in weeks. And much of the effort was less about building something new and more about removing what we no longer needed. Simplifying. Deleting. Unwinding complexity that had accumulated over years.
That was a lesson I’ve carried since: unwinding complexity is much faster than building it.
Once the streamlined pipeline was in place, the workflow changed. When any pending work was tested, we would release it immediately. I’ll write separately about the process and communication changes that made this flow smoothly — that’s its own post.
The results were immediate and significant.
Within about a month, we went from one release per month to several releases per day.
These changes had a cumulative and dramatic impact on productivity. Over the first quarter of 2024, the number of completed work items reaching production nearly doubled. And, it kept going up. By the end of 2024, we had a sustained throughput gain of roughly 4 times compared to our previous baseline.
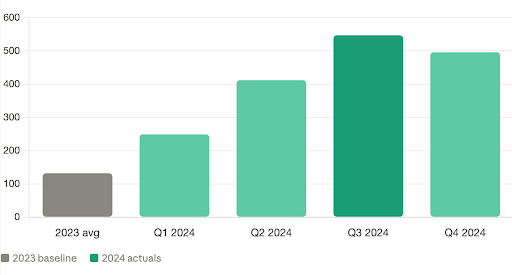
Here’s the part that surprised me most: our bug rate didn’t go up. It effectively went down. We had roughly the same number of bugs per month as before, but we were shipping four times the work. The same absolute number of issues across four times the output is a dramatically better ratio. That wasn’t luck, but we had not predicted it.
I can’t say for certain why this occurred. I postulate that when you ship in smaller pieces, faster, you reduce the surface area of potential failure. You find issues earlier, while context is fresh. And you avoid the hidden complexity that comes from batching changes together for weeks. Shipping faster didn’t make us sloppy. It made us sharper. LEAN manufacturing has known this for decades — small batch sizes and reduced work in progress are foundational principles for a reason. We just applied them to software.
Harder to measure — but just as real — was what happened to the team.
Developers were seeing their work reach customers quickly. The feedback loop tightened. The reward came faster. They spent less time navigating process and more time solving problems.
Any developer will tell you: they want to spend their time solving problems — not fighting the pipeline or the process, not watching their work sit untouched for months.
Momentum creates pride. Pride creates ownership. Ownership creates quality.
We didn’t do this because we wanted to go faster. We did it because we wanted a healthier system that we enjoyed working in. The consequence was a system where progress was visible, learning happened quickly, and we didn’t have to choose between reliability and delivery.
We still care deeply about quality. That didn’t change. What changed is how we achieve it.
In “The Phoenix Project,” Gene Kim describes how work piling up at a single constraint compounds across the entire system. QA was our bottleneck by design — a safety net the organization treated as a feature, not a flaw. That wasn’t wrong. It produced a near-zero production bug rate. But it came with a cost to our team enjoyment and throughput that we eventually decided to address differently. Relieving that constraint didn’t lower our standards. It let us meet them more consistently.
Sometimes the safest thing you can do isn’t to slow down. It’s to shorten the distance between start and finish – in our case – building, shipping, and learning.
If progress only shows up in big moments, it’s going to feel slow. Make it visible more often.
In my next post I will share how we redesigned our process to reduce the human communication our workflow required, and what happened when we did.
